In our QNX 4.25 system we suspect we are having some intermittent network issues based on the way our system is behaving in the field (for reference, we have between 12-14 nodes depending on system configuration). I’m trying to figure out how to best assess the health of my network in the field. Our network switches can give us a little bit, but not enough. We can also have technicians inspect cables and do consistency checks, but again I need to go deeper (these inspections usually don’t turn up much). In IP networks you can use wireshark/tcpdump and get a packet capture that you can usually get really good information out of. Since we use FLEET and FLEET is at Level 2 and not an IP-based protocol, I’m trying to figure out if there’s a way for me to glean any useful information from a pcap of FLEET. If someone knows the format of the protocol (or knows where I can find it), I can parse it myself from there. Or if you have any other ideas I’d love it if you’d share them.
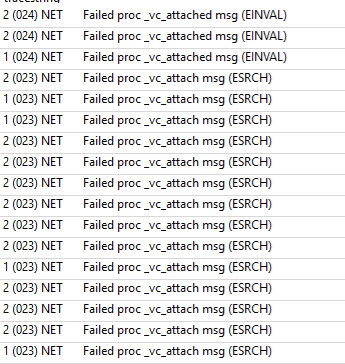
Also, if you happen to know what these messages in the traceinfo log mean, that would be useful. We suspect these might be related, but we don’t know what they mean.
From the help documentation on qnx_vc_attach() we know that ESRCH means “pid doesn’t exist or may not be a vid or proxy”, which I’m guessing means the node we’re trying to establish the virtual circuit to isn’t reachable, but I can’t figure out EINVAL. The help says it means “The virtual circuit buffer was too big”, but I don’t see how that can be possible if it’s correctly sized sometimes (since this error is inconsistent).
Strangely, this is more difficult for me to get my head around than QNX 2 which is much older. My intuition is that this must be network hardware related. I don’t think that the FLEET protocol was documented. I suspect it was similar to the QNX 2 network protocol which also wasn’t documented. You might be able to figure it out using wireshart. In case you are wondering about what a VC is, I can explain that.
In QNX 2 and 4 to send a message to another task/process on the same node, it is only necessary to know the task/process’s task/process id, tid or pid. QNX 6 has threads which makes things more complicated. You find the tid/pid using some mechanism and then just use the send() primitive. The name was changed in QNX 4 to not conflict with the TCP/IP send().
In order to send to a process on another node there has to locally be a tid/pid to point send() at. This is done by creating a virtual circuit or VC. In QNX 4 the virtual circuits are created automatically when you call open on a remote node, eg fopen(“//4/somefile_or_device”, “r”); There is some interaction between proc and the network manager to accomplish this.
VC’s are very fragile as they depend on a connected network. When a connection fails the VC has to be cleaned up which can cause confusion in the process. Sends and Receives will return errors. The messages you are seeing are likely because of some network problem. This could be a physical hardware problem or a cable/parameter issue.
Not that this is specifically related but a few years ago I diagnosed a problem for the US Post Office at one of their package handling sites. There were two identical QNX 6 systems. Identical including their private IP addresses. The systems were both connected to the same WAN. This was OK since they were separated by routers, or so it seemed. One of the systems kept losing connection. After staring at ARP packets for a while I decided there must be a cabling problem, which there was. One of the systems was connected directly into the WAN. It’s ARP packets bled over telling the system where to find it’s IP’s. This messed up an IP table on the other system which is what caused the problem. All we had to do to fix it was to find the misconnected cable.