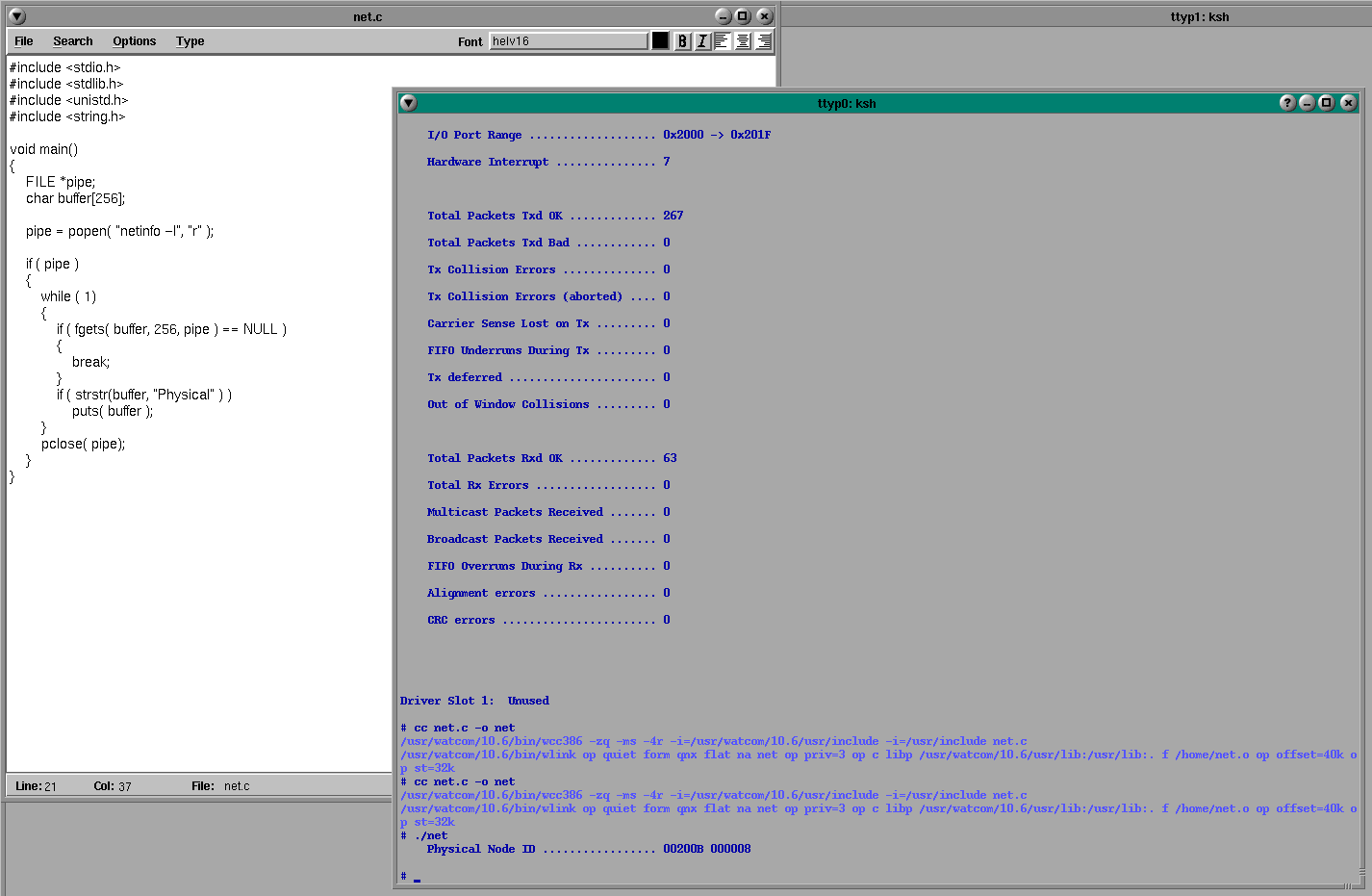
Hello all,
I have some systems running on QNX 4.25 on a single board computer using Compact Flash as their disk. We are encountering a fairly difficult issue with corrupted files and drives on these systems.
Symptoms we’re seeing:
- Corrupted files: we have seen some files get corrupted such as /bin/netinfo and /bin/awk (they give either an Input/output error or a exec format error when you try to run them by hand, and the checksum of the file is wrong as well). I give these two specific files as examples because we use them in our applications via popen() so it’s more obvious when they’re not working (more on that later). We have also seen /bin/sh be corrupted, which causes the node to hang during the boot sequence when the node tries to exec the sysinit file. Sometimes these files get corrupted and stay corrupted, other times they’re fine one minute and corrupt the next (and they go in-and-out like that).
- Corrupted drives: sometimes when the node is rebooted it is completely unbootable and gives a message of “Reboot and select proper boot device”.
- Application instability: some of our applications stop responding correctly; our users have described it as “going to sleep” (the nodes and applications do not sleep by design or configuration, so this isn’t expected).
System configuration:
We have various configurations in the field, and the symptoms that they see are all similar but varied (as you can see above we have a variety of symptoms, but I think they all tie back to a common issue). Here are some of the configurations we have:
- Some nodes run QNX 4.25 2009 CD, some run the QNX 4.25 2011 CD.
- Some nodes run on a single-core processor, some run on an Intel Core 2 Duo (dual-core)
- Some of the nodes use different parameters for Fsys. Some just run /bin/Fsys -Hdisk## -A -r8000, others do /bin/Fsys -Hdisk## -A -r8000 -c0k -d0
- The size of the Compact Flash cards varies from as low as 256MB to up to 8GB. I believe that all are either 256MB, 512MB, 2GB, or 8GB.
- Some of the boards use the Fsys.atapi driver, some use Fsys.eide. In general the single-core boards are using Fsys.eide and the dual-core are using Fsys.atapi (not sure why, to be honest), but I don’t know that this is 100% consistent.
Things we’ve considered:
- Hardware issues. The obvious culprit, but it doesn’t seem to be the case here (or at least not always). Some of these drives are fairly old so it could be wear-and-tear, but some of them are new (not new enough to be infant mortality, but not old enough for it to be wearout), and verified good before being put into service. It is possible that some of these failures could be attributed to wearout/old cards, but not all of them (in fact I would say most of them are not due to wearout/old cards).
- Hard reboots/power failures. We always use soft shutdown and aren’t having power failures, but still have these issues.
- Dual core processor. I’m fairly sure that QNX 4.25 wasn’t designed with dual core processors in mind (not 100% sure if it straight-up doesn’t support them though), but we have issues on single-core processors also. The failure modes aren’t exactly the same (for example we’ve only seen drive corruption on the dual-core boards so far), but we’ve had problems with both configurations so we think that the dual-core processor isn’t the only factor.
Some observations:
- These issues started to be reported (or at least have been happening with greater frequency) since the introduction of a software update. Reviewing the update the main thing that sticks out to me is that we started using popen(), which we do to open a read pipe to run the netinfo command to get some network statistics, and then pipe that output to grep and then awk to get specific statistics that we care about. I especially mention that because sometimes we’ll see errors in the terminal of “popen: Input/output error”, which also seems to point to popen(). We’ve checked the code and we did code the use of popen() correctly, so we don’t think it’s a bug in how we’re using that function call (i.e. we’re ensuring that we close the pipe correctly with pclose(), etc).
- I would like to note that the issues may not be tied to the software update and may also not be tied to popen(), these are just possibilities that we’ve considered.
- We’ve seen these issues happen while the nodes are running without any reboot, shutdown, or power loss.
- /bin/Pipe is not running on these nodes. We’ve tried running it in our lab but it doesn’t seem to solve the problem though.
- The systems having issues do write to the drive (fopen() calls mostly, though I suspect that popen() also either writes to the drive or interacts with it somehow), but we have some systems that do not do any writes to the drive (no fopen(), no popen()), and these systems do not have these same issues, which makes me think that writing to the drive is tied to this.
- Doing some research I discovered that popen() (in QNX 4.25 at least) is not thread-safe. Our applications are single-threaded only, but I also discovered that Fsys by default runs with 4 threads, and I’ve started to wonder if maybe somehow this could be related. It doesn’t seem possible, but at this point I’m expanding my ideas of what is possible.
Questions/help needed:
These issues are fairly intermittent, but happening enough for it to be a major issue. At this point we’re doing a root cause analysis and a major investigation. We’re doing a lot of testing in our laboratory, and have seen these failures a couple of times now, but we haven’t been able to determine a root cause and the reproductions have been infrequent enough that we haven’t been able to determine a pattern to get ourselves to a root cause. I suspect that this is tied to some kind of issue with Fsys, either parameters that we could tweak, or a bug in it that we could perhaps work around/design around, and if I was able to reproduce the issue more frequently/repeatably I think I could figure out how to do that, but I haven’t had success with that so far.
What I could use help with is this:
- Do you have any ideas about what I should look at regarding contributing factors beyond what I’ve listed here, something that I’m not considering, maybe?
- I would greatly appreciate any ideas for tests that I could run that could help me reproduce this issue repeatably. I’m open to writing any kind of shell script or C program (or anything else that would help), or if there’s some existing utility/tool that could help I’m open to that as well.
Any ideas, information, pointing me in the right direction, etc. would be greatly appreciated. Thank you!